Using CafeTran to re-segment a legacy TMX file Thread poster: CafeTran Training (X)
|
|---|
CafeTran Training (X)
Netherlands
Local time: 13:03
Sometimes you receive a legacy TMX file that has been segmented paragraph-wise, while you want to use it for your current translation project that has been segmented after every sentence.
Here are two videos that show you how to re-segment the legacy TMX file (note that TU attributes will get lost, but how relevant is that for legacy TMX files anyway?)
Re-segmenting a TM ... See more Sometimes you receive a legacy TMX file that has been segmented paragraph-wise, while you want to use it for your current translation project that has been segmented after every sentence.
Here are two videos that show you how to re-segment the legacy TMX file (note that TU attributes will get lost, but how relevant is that for legacy TMX files anyway?)
Re-segmenting a TM - Part 1
https://youtu.be/h7xEoARMKB0
Re-segmenting a TM - Part 2
https://youtu.be/gEBbA4okhdk
[Edited at 2017-05-25 18:10 GMT] ▲ Collapse
| | | | CafeTran Training (X)
Netherlands
Local time: 13:03
TOPIC STARTER | Improved regular expression | May 27, 2017 |
Here's an improved regular expression, that will cover texts like:

Expression: (?<=[a-z%\d\\)][\.\!\?]) (?=([a-z]?[A-Z]))
Result:
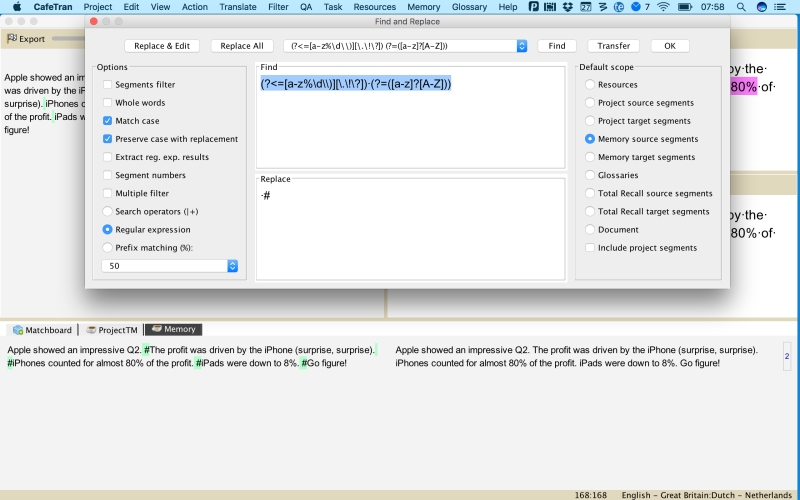
[Edited at 2017-05-27 08:27 GMT]
| | | | | Improve it a little more. And then again... | May 27, 2017 |
CafeTran Training wrote:
Here's an improved regular expression
Using regexes to achieve this will be an endless pain:

My plan still is:
Open the wretched TMX file in CafeTran's Edit TMX mode
Export as HTML (other export format may be possible)
Open the HTML in Word, save as .docx
Select both Word columns one by one, and open them in CafeTran one by one, sentence segmentation enabled
Save
Align (auto)
Using the CafeTran segmentation rules is a lot easier than trying to write a rather complicated regex, but the main advantage is, that it will be compliant with the source document(s).
I'm still trying to avoid aligning - even though it shouldn't present a problem - but so far no luck.
Cheers,
Hans
| | | | Michael Beijer 
United Kingdom
Local time: 12:03
Member
Dutch to English
+ ...
CafeTran Training wrote:
Sometimes you receive a legacy TMX file that has been segmented paragraph-wise, while you want to use it for your current translation project that has been segmented after every sentence.
Here are two videos that show you how to re-segment the legacy TMX file (note that TU attributes will get lost, but how relevant is that for legacy TMX files anyway?)
Re-segmenting a TM - Part 1
https://youtu.be/h7xEoARMKB0
Re-segmenting a TM - Part 2
https://youtu.be/gEBbA4okhdk[Edited at 2017-05-25 18:10 GMT]
To be honest, I don't understand what you're doing. When you re-segment a TMX file that was segmented on paragraphs in the past, what do you do with instances where the translator merged several sentences in the src into a single sentence in the target? Your whole system seems to be based on the assumption that there will always be a one-to-one correspondence.
Michael
| | |
|
|
|
CafeTran Training (X)
Netherlands
Local time: 13:03
TOPIC STARTER | Not a problem | May 28, 2017 |
Michael Joseph Wdowiak Beijer wrote:
To be honest, I don't understand what you're doing. When you re-segment a TMX file that was segmented on paragraphs in the past, what do you do with instances where the translator merged several sentences in the src into a single sentence in the target? Your whole system seems to be based on the assumption that there will always be a one-to-one correspondence.
Michael
That's true, Michael. For the cases that you mention, you'll have to use a slightly different procedure:
https://cafetran.freshdesk.com/support/discussions/topics/6000048974
Have a nice Sunday!
Hans
| | | | CafeTran Training (X)
Netherlands
Local time: 13:03
TOPIC STARTER | Improve a little more, and more, and more ... | May 28, 2017 |
Meta Arkadia wrote:
Using regexes to achieve this will be an endless pain:
Our whole life can be an endless pain. Luckily, it doesn't have to...
Adapting the necessary regular expressions for different types of texts (e.g. German legal texts versus English marketing documents) offers a nice way to optimise the result of the re-segmentation.
BTW: How do you think CafeTran segments source texts during import? My guess is that it uses regular expressions for this.
| | | | | Regexes, and quite a bit more | May 28, 2017 |
CafeTran Training wrote:
How do you think CafeTran segments source texts during import? My guess is that it uses regular expressions for this.
CafeTran does use regular expressions, but well-structured ones in a mark-up language, srx files. What you're trying to do is create one regex for all languages. It's doomed.
My suggestion is to use CafeTran's segmentation rules. That makes sense, because we're going to use the resulting TMX file in CafeTran. And then align the two segmented files. That makes sense, because aligners use "smart" rules nowadays. Just ask Andras. The aligned file will still have to be checked, though, which isn't very difficult, and probably not very time-consuming.
Cheers,
Hans
| | | |
BTW: How do you think CafeTran segments source texts during import? My guess is that it uses regular expressions for this.
BTW, I think you are right.
In the SRX (Segmentation Rules eXchange) specification file format, it is stated "the segmentation rules themselves are represented using regular expressions." - http://www.ttt.org/oscarstandards/srx/srx10.html
CT uses SRX.
| | |
|
|
|
CafeTran Training (X)
Netherlands
Local time: 13:03
TOPIC STARTER | Demo purposese only | May 28, 2017 |
Meta Arkadia wrote:
What you're trying to do is create one regex for all languages.
Of course not. I'm only demonstrating a technique. No way that I'm trying to create a universal regex for segmenting. Like I wrote: different languages and different text types require different segmentation rules.
| | | | CafeTran Training (X)
Netherlands
Local time: 13:03
TOPIC STARTER | Educated guess | May 28, 2017 |
Jean Dimitriadis wrote:
BTW: How do you think CafeTran segments source texts during import? My guess is that it uses regular expressions for this.
BTW, I think you are right.
In the SRX (Segmentation Rules eXchange) specification file format, it is stated "the segmentation rules themselves are represented using regular expressions." - http://www.ttt.org/oscarstandards/srx/srx10.html
CT uses SRX.
Yes, Jean, it was an educated guess (I already had a look at these rules in the CT folder long ago).
@Van den Broek: Actually it was me who suggested to use CT's segmenting rules. But you're welcome on my party too, Hans. (Please bring your own drinks.)
And, BTW, please feel free to use your own, preferred solution. I'm merely demonstrating some techniques here. If you don't like them, don't use them. Perhaps others can use some snippets that will come in handy someday.
| | | |
CafeTran Training wrote:
Like I wrote: different languages and different text types require different segmentation rules.
So far, you used one regex for both source language and target language.
It cannot be done. Not your way.
Cheers,
Hans
| | | | To report site rules violations or get help, contact a site moderator: You can also contact site staff by submitting a support request » Using CafeTran to re-segment a legacy TMX file | Wordfast Pro |
|---|
Translation Memory Software for Any Platform
Exclusive discount for ProZ.com users!
Save over 13% when purchasing Wordfast Pro through ProZ.com. Wordfast is the world's #1 provider of platform-independent Translation Memory software. Consistently ranked the most user-friendly and highest value
Buy now! » |
| | TM-Town |
|---|
Manage your TMs and Terms ... and boost your translation business
Are you ready for something fresh in the industry? TM-Town is a unique new site for you -- the freelance translator -- to store, manage and share translation memories (TMs) and glossaries...and potentially meet new clients on the basis of your prior work.
More info » |
|
| | | | X Sign in to your ProZ.com account... | | | | | |






